
Кицмен Дмитро Романович
Студент кафедри Технічної Кібернетики
КПІ ім. Ігоря Сікорського
місто Київ
Анотація: в статті приведені основні механізми за допомогою яких реалізуються функціональні та не функціональні особливості різноманітних NoSQL баз даних. Показані недоліки та переваги існуючих рішень. Розроблений алгоритм вибору сховища залежно від вимог системи.
Ключові слова: NoSQL, база даних, доступність, консистентність, розподіленість, реплікація, шардинг.
Вступ
Сьогодні дані продукуються та споживаються в безпрецедентному масштабі. Це призвело до створення нових підходів для управління даними, що підпадає під термін NoSQL системи баз даних для обробки зростаючого обсягу даних та складних запитів. Проте гетерогенність та різноманітність численних існуючих систем перешкоджають добре обґрунтованому підбору сховища даних, яке б відповідало конкретному прикладному контексту. Таким чином, ця стаття оглядає сукупність факторів: замість протиставлення особливостей реалізації окремих представників ми пропонуємо порівняльну класифікаційну модель, яка стосується функціональних та не функціональних вимог до методів та алгоритмів, що використовуються в базах даних NoSQL. Ця стаття дозволить нам отримати просту систему класифікаторів, яка допоможе розробникам і дослідникам фільтрувати потенційних кандидатів для використання в якості сховища даних в різноманітних системах. В ній здійснена порівняльна характеристика недоліків та переваг популярних NoSQL баз даних в рамках реалізації ними CAP теореми.
Традиційні системи управління реляційними базами даних (СУБД) забезпечують потужні механізми зберігання та обробки структурованих даних за допомогою сильної консистентності та гарантій транзакцій і досягли неперевершеного рівня надійності, стабільності та підтримки після десятиліть розробки. Проте останніми роками корисні дані в деяких областях застосування стали настільки великими, що їх не можна зберігати або обробляти за допомогою традиційних баз даних. Користувацький контент у соціальних мережах або дані, отримані з великої кількості датчиків, є лише двома прикладами цього явища, яке зазвичай називають великими даними. Клас нових систем зберігання даних, здатних впоратися з великими даними, під терміном бази даних NoSQL, забезпечують горизонтальну масштабованість та більш високу доступність, ніж реляційні бази даних. Проте ці переваги існують завдяки суттєвим недолікам – ми жертвуємо деякими можливостями запитів та відсутністю гарантій консистентності. Ці компроміси є ключовими для систем, орієнтованих на сервіс-орієнтовані обчислення та системи обслуговування, оскільки будь-яка стабільна служба може бути лише настільки масштабованою та відмовостійкою, наскільки таким є її сховище даних.
Є десятки баз даних системи NoSQL, і важко стежити за тим, чим вони відрізняються, оскільки деталі їхнього впровадження швидко змінюються і набори їхніх функцій з часом розвиваються. Таким чином, у цій статті ми намагаємося надати огляд специфіки NoSQL, обговоривши застосовані поняття, а не системні особливості, і вивчимо вимоги, які зазвичай пред'являються до систем баз даних NoSQL, методи, що використовуються для виконання цих вимог, та компроміси, які мають бути застосовані в процесі. Наша увага зосереджена на сховищах виду «ключ-значення», документно-орієнтованих та стовбцево-орієнтованих сховищах, оскільки ці категорії NoSQL охоплюють найбільш релевантні методи та проектні рішення в області масштабованого управління даними.
Високорівнева класифікація
Найбільш часто використовуваною відмінністю при порівнянні NoSQL баз є спосіб їх зберігання та надання доступу до даних. Кожна система, охоплена цим документом, може бути класифікована як сховище ключів та значень, документне сховище або стовпцево-орієнтована база даних.
Сховища типу «ключ-значення»
Такі сховища складаються з наборів пар ключ-значення з унікальними значеннями ключів. Завдяки цій простій структурі, вони підтримують тільки операції вставки та зчитування даних. Оскільки характер збережених даних є очевидним для бази даних, то найпростіші представники цього сімейства баз даних не підтримують операції окрім простого CRUD (Створення, Читання, Оновлення, Видалення). Тому такі сховища часто називаються безсхемними: будь-які припущення про структуру збережених даних неявно програмуються в логіці додатку (schema-on-read) і неявно визначені за допомогою мови визначення даних(schema-on-write).
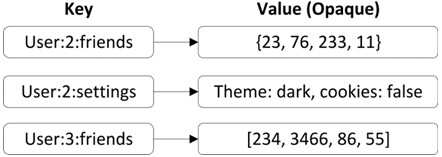
Рис. 1 Приклад формату збереження даних в сховищі типу «ключ-значення»
Сховища документів
Документні сховища - це сховища з записами ключ-значення, які обмежують значення напівструктурованими форматами, такими як документи JSON. Це обмеження в порівнянні з сховищами ключів та значень дає велику гнучкість у доступі до даних. Можна не тільки отримати весь документ за його ідентифікатором, але й витягувати лише частину документа, наприклад вік клієнта, а також виконувати такі запити, як агрегація або навіть повнотекстовий пошук.

Рис. 2 Приклад формату збереження даних в документному сховищі
Стовпцево-орієнтовані сховища
Такі сховища успадкували своє ім'я від зображення, яке часто використовується для пояснення базової моделі даних: реляційної таблиці з багатьма рідкісними стовпцями. Однак, технічно, такі сховища знаходяться ближче до розподіленої багаторівневої сортованої карти: ключі першого рівня ідентифікують рядки, які самі складаються з пар основних значень. Ключі першого рівня називаються ключами рядків, ключі другого рівня називаються ключами стовпців. Ця схема зберігання робить таблиці з довільним числом стовпців можливими, тому що немає ключів стовпця без відповідного значення. Отже, нульові значення можуть зберігатися без будь-яких накладних витрат пам’яті.
Кожна комірка у таблиці (тобто кожне значення, яке доступне за допомогою комбінації ключа стовпця та рядку) може бути версійована за допомогою міток часу або номерів версій. Важливо відзначити, що більша частина інформації сутності зберігається не тільки в значеннях але й в ключах.
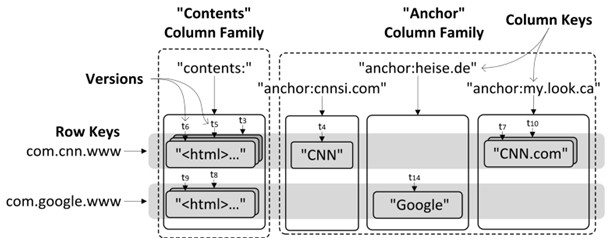
Рис. 3 Приклад формату збереження даних в стовпцево-орієнтованому сховищі
Техніки реалізації аспектів CAP теореми
Кожна істотно успішна база даних призначена для певного класу додатків або для досягнення певної комбінації бажаних властивостей системи. Проста причина, чому існує так багато різних систем бази даних, полягає в тому, що будь-яка система не може досягти всіх бажаних властивостей одночасно. Традиційні бази даних SQL, такі як PostgreSQL, були побудовані для забезпечення повного функціонального пакета: дуже гнучка модель даних, складні можливості запитів, включаючи об'єднання, обмеження глобальної цілісності та транзакційні гарантії. На іншому кінці дизайнерського спектру рішень є такі сховища, як Dynamo, яка масштабує дані та обсяг запитів, а також забезпечує високу пропускну здатність читання та запису, низьку затримку, але не надає практично інших функцій, крім простого пошуку.
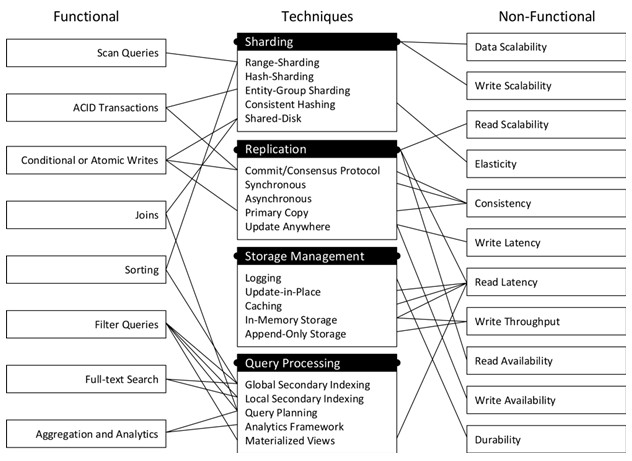
Рис. 4 Техніки, які використовуються в NoSQL базах даних і функціональні та не функціональні особливості, які вони забезпечують
Ми розглянемо архітектурні рішення які використовуються в розподілених системах баз даних, зосереджуючи увагу на шардингу, реплікації, керуванні сховищем та обробці запитів. Ми дослідимо доступні методи та обговоримо, як вони пов'язані з різними функціональними та нефункціональними властивостями (цілями) систем управління даними.
Шардинг
Кілька поширених систем реляційних баз даних, таких як Oracle RAC або IBM DB2 pureScale, покладаються на архітектуру спільного диска, де всі вузли бази даних мають доступ до одного і того ж центрального сховища даних (наприклад, NAS або SAN). Таким чином, ці системи забезпечують консистентні дані у будь-який час, але водночас їх також важко масштабувати. На відміну від цього, NoSQL системи баз даних, на які орієнтована ця стаття, побудовані на основі архітектури, що не має нічого спільного, тобто кожна система складається з багатьох серверів із власною пам'яттю та дисками, які підключені через мережу. Таким чином, висока масштабованість при хорошій пропускній здатності та високих обсягах даних досягається шляхом відокремлення (розбиття) даних на різні вузли (елементи) в системі. Існує три основні методи розподіленої обробки даних: шардинг по діапазонах, хешах та сутностях. Для того, щоб зробити ефективні сканування можливими, дані можна розділити на упорядковані та сусідні діапазони значень за діапазоном. Однак цей підхід вимагає певної координації через майстра, який керує виконанням задач. Щоб забезпечити еластичність, система повинна мати можливість автоматично виявляти і вирішувати точку доступу, додатково розділяючи перевантажений елемент обробки даних.
Реплікація
З точки зору САP, звичайні СУБД часто є системами з підтримкою СА, що працюють в односерверному режимі: вся система стає недоступною при відмові машини. Системні оператори захищають цілісність та доступність даних через дорогі, але надійні високотехнологічні апаратні засоби. На відміну від цього, системи NoSQL, такі як Dynamo, BigTable або Cassandra, призначені для обміну даними та запитами, які неможливо обробляти однією машиною, і тому вони працюють на кластерах, що складаються з тисяч серверів. Використовується низькотехнологічне обладнання, оскільки воно значно економічно ефективніше, ніж високотехнологічне. Оскільки збої неминучі і часто зустрічаються в будь-якій масштабній розподіленій системі, програмне забезпечення має справлятися з ними щодня. У 2009 році співробітник Google Jeff Dean заявив, що типовий новий кластер у Google виявляє тисячі несправностей жорсткого диска, 1000 збоїв однієї машини, 20 збоїв зі серверними стійками та декілька мережевих розділів через очікувані та несподівані обставини лише в перший рік. Було повідомлено про нещодавні випадки мережевих розділів та відключень у великих центрах обробки даних. Реплікація дозволяє системі підтримувати доступність та довговічність у разі таких помилок. Але зберігання тих самих записів на різних машинах (реплікаційних серверах) в кластері вказує на проблему синхронізації між ними і, таким чином, компроміс між узгодженістю, з одного боку, і затримкою та доступністю з іншого.
Керування фізичним сховищем
Щоб забезпечити найкращу продуктивність, системи баз даних повинні бути оптимізовані для носія інформації, який вони використовують для обслуговування та збереження даних. Це, як правило, основна пам'ять (ОЗП), твердотілі накопичувачі (SSD) та жорсткі диски (HDD), які можуть використовуватися в будь-якій комбінації. На відміну від СУБД на підприємствах, розподілені бази даних NoSQL уникають спеціалізованих архітектур спільного диска на користь кластерів, що не мають нічого подібного, на основі стандартних серверів (із застосуванням стандартних носіїв інформації). Пристрої зберігання, як правило, візуалізуються як "піраміда" (див. Рисунок 5). Існує також набір кеш-пам'яті (наприклад, кеш-пам'ять процесора L1-L3 та буфер диска, не показані на малюнку), які лише неявно використовуються за рахунок добре розроблених алгоритмів баз даних, що сприяють покращенню локалізації даних. Однією з причин розмаїття баз даних NoSQL є дуже різноманітні вартість і характеристики продуктивності оперативної пам'яті, SSD та жорстких дисків, а також різноманітні стратегії використання їх сильних сторін (керування зберіганням даних). Управління сховищами даних має просторовий вимір (де зберігати дані) та часовий вимір (коли зберігати дані). Update-in-place і add-only-IO - це два взаємодоповнюючі просторові методи організації даних; in-memory призначає оперативну пам'ять як місце розташування даних, тоді як логування - це тимчасова техніка, яка відокремлює основну пам'ять та постійне зберігання, і таким чином забезпечує контроль над тим, коли дані дійсно зберігаються.
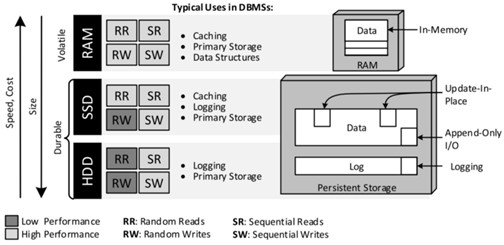
Рис. 5 «Піраміда» сховища і її роль в NoSQL базах даних
У своїй основній праці "кінець архітектурної епохи", Stonebraker та співавт. виявили, що в типових СУБД лише 6,8% часу виконання витрачається на "корисну роботу", а решта витрачається на:
- керування буфером (34,6%), тобто кешування, щоб пом'якшити повільний доступ до диску
- фіксацію (14,2%), щоб захистити загальні структури даних від стану перегонів, викликаних багатопотоковою обробкою
- блокування (16,3%), щоб гарантувати логічну ізоляцію транзакцій
- логування(1,9%), щоб забезпечити довговічність у разі несправностей
- оптимізації, написані розробниками СУБД(16,2%)
Таблиця 1
Порівняння функціональних і не функціональних вимог сховищ
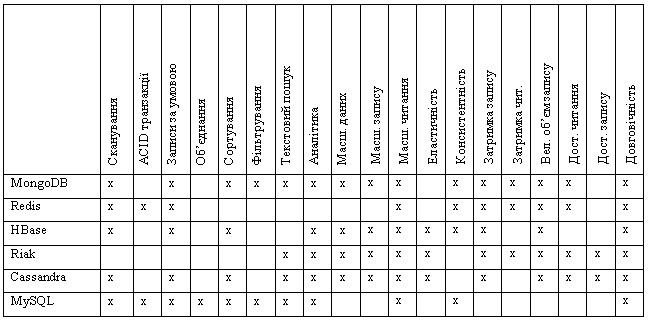
Таблиця 2
Порівняння технік, які використовуються для забезпечення фунцкіональних та нефункціональних характеристик
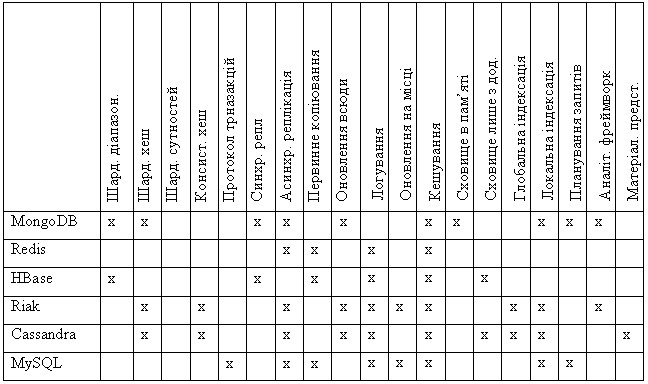
Обробка запитів
Можливості запитів до бази даних NoSQL головним чином випливають із її моделі розподілу, гарантій послідовності та моделі даних. Первинний пошук ключів, тобто отримання елементів даних за унікальним ідентифікатором, підтримується кожною системою NoSQL, оскільки вона сумісна з діапазонними, а також з хеш-розділами. Фільтровані запити відображають всі елементи (або проекції), які відповідають предикату, вказаному для полів сутності з однієї таблиці. У їх найпростішому вигляді вони можуть бути здійснені шляхом фільтрування таблиці. Для хеш-розподілених баз даних це означає, що кожен розділ виконує передбачене сканування і результати зливаються. Для розділених систем по діапазонам значень для вибору розділів можна використовувати будь-які умови для вибору атрибута діапазону.
Щоб обійти неефективність O(n) сканування, можна використовувати вторинні індекси. Вони можуть бути або локальними вторинними індексами, які керуються у кожному розділі або глобальними вторинними індексами, які індексують дані по всіх розділах. Оскільки глобальний індекс сам по собі повинен розподілятися по розділам, для підтримки послідовного вторинного індексу необхідні повільні та потенційно недоступні протоколи виконання транзакцій. Тому на практиці більшість систем лише пропонують кінцеву послідовність для цих індексів (наприклад, Megastore, Google App Engine Datastore, DynamoDB) або взагалі не підтримують їх (наприклад, HBase, Azure Tables). При виконанні глобальних запитів за локальними вторинними індексами запит може бути націлений лише на підмножину розділів, якщо предикат запиту і правила розподілу бази співпадають. Інакше результати повинні бути зібрані шляхом виконання запитів окремо на вузлах бази, а потім агрегації цих окремих результатів в загальний. Наприклад, таблиця користувача з розподілом по віку може обслуговувати запити, що мають умови рівності для віку з одного розділу, тоді як запити над іменами потрібно виконувати в кожному розділі. Спеціальним випадком глобальної вторинної індексації є повнотекстовий пошук, в якому вибрані поля або повні дані передаються в інверсний індекс бази даних (наприклад, MongoDB) або на зовнішню пошукову платформу, таку як ElasticSearch або Solr (Riak Search, DataStax Cassandra).
Планування запитів - це завдання оптимізації плану запитів для мінімізації витрат на виконання. Для агрегації та об'єднань таблиць планування запитів має важливе значення, оскільки ці запити дуже неефективні та їх важко реалізувати в коді програми. Багато існуючих методів обробки реляційних запитів в основному не використовуються в поточних системах NoSQL з двох причин. По-перше, моделі типу ключ-значення та стовпцеві-орієнтовані сховища зосереджені навколо CRUD і операції сканування здійснюються над первинними ключами, що залишає мало місця для оптимізації запитів. По-друге, більшість робіт з обробки розподілених запитів фокусується на робочих навантаженнях OLAP (онлайн-аналітична обробка), що сприяють збільшенні пропускної здатності за менший час затримки, тоді як оптимізацію запитів для одиночного вузла нелегко застосувати для розподілених та реплікованих баз даних. Проте залишається відкритим завдання узагальнити велику частину застосованих методів оптимізації запитів, особливо в контексті документно-орієнтованих баз даних. (В даний час лише RethinkDB може виконувати загальні Θ-об'єднання. У MongoDB є підтримка лівих та зовнішніх об’єднань в рамках агрегації, і CouchDB дозволяє об'єднуватись із заздалегідь задекларованими проекціями)
Схема вибору сховища залежно від функціональних особливостей
Запропонована схема є засобом абстракції, який можна використовувати для класифікації систем бази даних за трьома параметрами: функціональні вимоги, нефункціональні вимоги та методи, що використовуються для їх реалізації. Ми стверджуємо, що ця класифікація добре характеризує багато систем бази даних і, таким чином, може бути використана для суттєвої протилежності різних систем бази даних. У таблиці 1 показано пряме порівняння MongoDB, Redis, HBase, Riak, Cassandra та MySQL у відповідних конфігураціях за умовчанням.
Методологія, яка використовується для ідентифікації конкретних властивостей системи, полягає у поглибленому аналізі загальнодоступної документації та літератури про системи. Крім того, деякі властивості повинні були оцінюватися шляхом вивчення баз кодів відкритого коду, а також аналізу результатів тестування незалежних експертів.
Порівняння висвітлює, як бази даних SQL і NoSQL призначені для виконання дуже різних потреб: RDBMS забезпечують незрівнянний рівень функціональності, тоді як база даних NoSQL перевершує нефункціональну сторону завдяки масштабованості, доступності, низькій затримці та / або високій пропускній здатності. Однак існує також велика різниця між базами даних NoSQL. Наприклад, Riak та Cassandra можуть бути налаштовані на виконання багатьох нефункціональних вимог, але вони в остаточному підсумку є послідовними та не мають багатьох функціональних можливостей, крім аналітики даних, а у випадку Cassandra - умовних оновлень. MongoDB та HBase, з іншого боку, пропонують посилену послідовність і більш складні функціональні можливості, такі як запити сканування і - тільки MongoDB фільтрує запити, але не підтримує доступність читання та запису під час розділів і, як правило, відображає більшу латентність читання. Redis, будучи єдиною нерозподіленою системою в даному порівнянні, крім MySQL, показує спеціальний комплект компромісів, зосереджений на здатності підтримувати надзвичайно високу пропускну здатність при низькій затримці, використовуючи структури даних в пам'яті та асинхронну реплікацію master-slave.
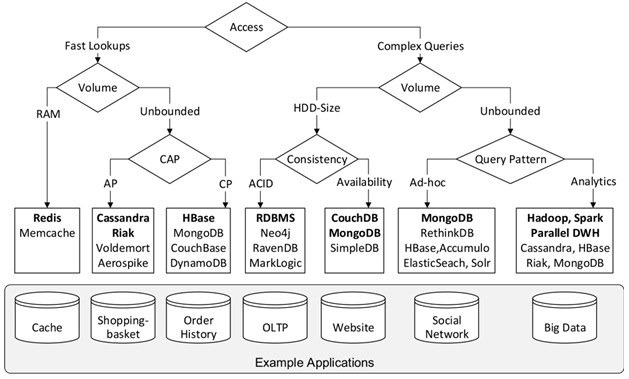
Рис. 6 Дерево прийняття рішення для вибору NoSQL сховища
Висновки
Вибір системи бази даних завжди означає вибір одного набору бажаних властивостей над іншим. Щоб розбити складність цього вибору, розроблено дерево рішень на рисунку 6, яке відображає компромісні рішення для прикладних програм та потенційно придатних систем бази даних. Вузли охоплюють програми від простого кешування (ліворуч) до аналізу Big Data (справа). Природно, що таке уявлення про проблемний простір не є повним, однак воно невизначено вказує на рішення для конкретної проблеми керування даними.
Перший етап класифікації у дереві знаходиться вздовж шаблону доступу програм: вони або залежать від швидкого пошуку (ліва половина) або вимагають більш складних запитів (праворуч). Швидкорозшукові додатки можна розрізнити за обсягом даних, який вони обробляють: якщо основна пам'ять однієї машини може містити всі дані, то, можливо, одна система, як Redis або Memcache, є найкращим вибором залежно від того, чи потрібна функціональність (Redis) або простота (Memcache). Якщо обсяг даних перевищує місткість пам'яті або може перевищувати обсяги пам'яті, то система, яка масштабується по горизонталі, може бути більш доцільною. Найважливішим рішенням у даному випадку є те, чи сприяти доступності (AP) чи послідовності (CP), як описано в теоремі CAP. Водночас системи, такі як Cassandra та Riak, можуть забезпечити постійний досвід, а системи, такі як HBase, MongoDB та DynamoDB, забезпечують сильну послідовність.
Права половина дерева охоплює додатки, що вимагають більш складних запитів, ніж просто пошук. Тут же ми спочатку розрізняємо системи за обсягом даних, який вони повинні обробляти: системи одного вузла або розподілені системи. Для звичайних OLTP (обробка онлайн-транзакцій) традиційні реляційні бази даних або графічні бази, такі як Neo4J, є оптимальними, оскільки вони пропонують семантику ACID. Однак, якщо доступність є необхідною, розподілені системи, такі як MongoDB, CouchDB або DocumentDB, є більш бажаними.
Якщо обсяг даних, які будуть оброблятись, перевищує можливості однієї машини, вибір правильної системи залежить від поширеного шаблону запиту: коли складні запити повинні бути оптимізовані для затримки, як, наприклад, у соціальних мережах, MongoDB дуже приваблива, тому що це полегшує експресивні ad-hoc запити. HBase і Cassandra також корисні в такому сценарії.
Таким чином, ми переконані, що розроблена модель ефективно допомагає виокремити з величезної кількості баз даних системи NoSQL на основі центральних вимог саме ту, яка буде найбільш доцільною при бажаних характеристиках системи, яка розробляється.
Список використаних джерел
1. Gilbert S: Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services, 2002.
2. Abadi D: Consistency Tradeoffs in Modern Distributed Database System Design, 2012
3. Chang F: Bigtable: A Distributed Storage System for Structured Data, 2006
Система вибору NoSQL сховища даних на основі бажаних характарних інформаційних систем /Кицмен Д. Р.
Об’єктом дослідження є NoSQL бази даних, їх функціональні та не функціональні особливості, механізми, за допомогою яких вони реалізовані. У статті приведена порівняльна характеристика та алгоритм вибору сховища, який базується на властивостях бажаної системи. Оскільки всім базам даних притаманні певні обмеження, необхідно чітко представляти недоліки та переваги різних сховищ, наявні в них механізми підтримки ACID, CAP.
Метою роботи є розробка методології вибору NoSQL сховища базуючись на функціональних вимогах системи, в якій воно буде використовуватись, а також можливостях, які надає та чи інша база даних. Для досягнення ефективної роботи системи пропонується аналізувати при виборі сховища не лише можливості вибірки даних, які вона надає, а також обладнання, на якому вона функціонує і механізми, які гарантують реалізацію функціональних та не функціональних вимог.
Ключові слова: NoSQL, база даних, доступність, консистентність, розподіленість, реплікація, шардинг.
Бібл. 3, іл. 6, табл 2
Система выбора NoSQL хранилища данных на основе желаемых хараткеристик информационной системы /Кицмен Д. Р.
Объектом исследования является NoSQL базы данных, их функциональные и нефункциональные особенности, механизмы, с помощью которых они реализованы. В статье приведена сравнительная характеристика и алгоритм выбора хранилища, основанный на свойствах желаемой системы. Поскольку всем базам данных присущи определенные ограничения, необходимо четко представлять недостатки и преимущества различных хранилищ, имеющиеся у них механизмы поддержки ACID, CAP.
Целью работы является разработка методологии выбора NoSQL хранилища основываясь на функциональных требованиях системы, в которой оно будет использоваться, а также возможностях, которые предоставляет та или иная база данных. Для достижения эффективной работы системы предлагается анализировать при выборе хранилища не только возможности выборки данных, которые она предоставляет, а также оборудование, на котором она функционирует и механизмы, гарантирующие реализацию функциональных и нефункциональных требований.
Ключевые слова: NoSQL, база данных, доступность, консистентнисть, распределенность, репликация, шардинг.
Библ. 3, ил. 6, табл 2
NoSQL data warehouse selection system based on the desired characterization of the information system / Kytsmen D. R.
The object of the study is the NoSQL database, its functional and non-functional features, the mechanisms by which they are implemented. The article presents a comparative characteristic and algorithm for selecting a repository based on the properties of the desired system. Since all databases have certain limitations, it is necessary to clearly identify the disadvantages and advantages of different storage facilities, the mechanisms that support ACID, CAP.
The goal of the work is to develop a methodology for choosing a NoSQL repository based on the functional requirements of the system in which it will be used, as well as the capabilities provided by this or that database. In order to achieve the efficient operation of the system, it is proposed to analyze, not only the possibility of sampling the data it provides, as well as the equipment on which it operates and the mechanisms that guarantee the implementation of functional and non-functional requirements, when selecting a storage facility.
Keywords: NoSQL, database, accessibility, consistency, distribution, replication, shading.
Ref. 3, pic. 6, tabl. 2