
Хоменко Микита Олександрович
студент 4 курсу, спеціальність «Комп’ютерні науки»
Донецький національний технічний університет,
місто Покровськ, Україна
Анотація: У даній статті розглядається метод опорних векторів, а також програмний додаток, який на його основі розпізнає літери друкованого тексту, що можуть бути написані різними шрифтами та мати різного роду спотворення.
Ключові слова: SVM, нейронні мережі, метод опорних векторів, розпізнавання образів.
В машинному навчанні, метод опорних векторів - це метод аналізу даних для класифікації та регресійного аналізу за допомогою моделей з керованим навчанням з пов'язаними алгоритмами навчання, які називаються опорно-векторними машинами. Модель ОВМ є представленням зразків як точок у просторі, відображених таким чином, що зразки з окремих категорій розділено чистою прогалиною, яка є щонайширшою. [1]
Формальніше, опорно-вектора машина будує гіперплощину, або набір гіперплощин у просторі високої або нескінченної вимірності, які можна використовувати для класифікації, регресії та інших задач. Інтуїтивно, добре розділення досягається гіперплощиною, яка має найбільшу відстань до найближчих точок тренувальних даних будь-якого з класів (так зване функціональне розділення), оскільки в загальному випадку що більшим є розділення, то нижчою є похибка узагальнення класифікатора [2, c. 125-137].
SVM використовується для завдань класифікації тексту, таких як призначення категорій та виявлення спаму. Він також зазвичай використовується для вирішення проблем розпізнавання зображень, особливо ефективним у розпізнаванні на основі аспектів та класифікації на основі кольорів. SVM також відіграє важливу роль у багатьох областях розпізнавання рукописних цифр, таких як служби автоматизації поштового зв'язку [3].
Розробка програми велась на мові програмування С#. Графічний інтерфейс створювався за допомогою API Windows Forms, який є частиною Microsoft .NET Framework.
Розроблювана програма призначена для розпізнавання зображень літер та цифр. Вхідні данні – зображення розміром 50х50 білого кольору з намальованими на них образами, що потребують розпізнавання.
Усі зображення для розпізнавання переводяться у їх чорно-білий еквівалент, тобто, для максимально точного розпізнавання рекомендується малювати зображення чи писати літери чорним кольором, або досить темним відтінком будь якого кольору палітри.
Далі, ці зображення перетворюються на вектор послідовності кольорів у пікселях, тобто, створюється масив об’єктів типу double, у кожному елементі котрого міститься значення від 0 (білий колір) до 255 (чорний колір). Всі значення, що знаходяться між цим діапазоном є відтінками сірого. Цей вектор – вектор ознак, що характеризує конкретний образ чи літеру, зображену на картинці.
Навчання мережі здійснюється через збереження даних векторів та інформації щодо належності до одного з класів у текстовий файл «LearningData.dat», та передачі їх для запису як еталонних значень для розпізнавання. Після навчання всі необхідні дані для розпізнавання літер записуються у файл «model.txt». З інформацією, що записана у файл «model.txt» йде порівняння та класифікація майбутніх даних, тому будь які зміни у ньому можуть привести до зміни точності розпізнавання образів даною програмою. Такий підхід до навчання дозволить зберігати дані та виключить необхідність повторного навчання нейронної мережи підчас кожного запуску програми.
Класифікація вхідних даних здійснюється на основі даних файлу «model.txt» та динамічної бібліотеки (dll) Тайванського національного університету, що може здійснювати розпізнавання методом опорних векторів образів різного типу з можливістю задання необмеженої кількості класів для розпізнавання.
Тестування розробленої програми проводиться у два етапи:
Перший – навчання нейронної мережі на тестовій вибірці.
Другий – перевірка роботи програми, за допомогою класифікації елементів перевірочної вибірки.
Для перевірки роботи програми було згенеровано 2 типи зображень з символами. Для тестової вибірки було створено набір зображень з літерами написаними шрифтами різного типу (див. рис. 1). Для перевірочної вибірки було створено навмисно спотворені та намальовані літери, що потребують класифікації (див. рис. 2).

Рисунок 1 – Навчальна вибірка для навчання нейронної мережі типу SVM
Рисунок 2 – Тестова вибірка для перевірки розпізнавання образів нейронною мережею типу SVM
Зовнішній вигляд програмного додатку зображено на рисунку 3. Даний інтерфейс спрощує доступ до елементів інтерфейсу Microsoft Windows за рахунок створення обгортки для існуючого Win32 API в керованому коді.
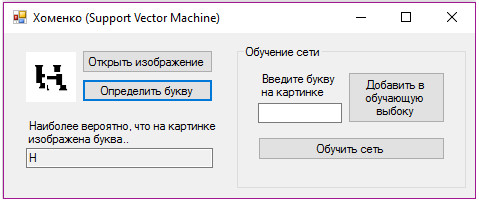
Рисунок 3 – Розпізнавання спотвореної літери «Н» розробленою програмою
Література:
1. Владимир Вьюгин. Математические основы теории машинного обучения и прогнозирования. — МЦМНО, 2013. — 390 с. — ISBN 978-5-4439-0111-4.
2. Ben-Hur, Asa, Horn, David, Siegelmann, Hava, and Vapnik, Vladimir; "Support vector clustering" (2001) Journal of Machine Learning Research.
3. Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, B. P. (2007). Section 16.5. Support Vector Machines. Numerical Recipes: The Art of Scientific Computing (вид. 3rd). New York: Cambridge University Press. ISBN 978-0-521-88068-8.