
Тищенко Ганна Валентинівна
студентка, ДВНЗ «ДонНТУ», Україна, м. Покровськ
Бишенко Юлія Анатоліївна
студентка, ДВНЗ «ДонНТУ», Україна, м. Покровськ
Анотація: Порівняно популярні системи збору даних з веб-ресурсів. Розроблено систему з урахуванням виявлених недоліків. Проаналізовано швидкодію цих систем.
Кожна компанія зацікавлена в інформації про ринок, на якому вона працює. Для розвитку потрібні дані, які допомагають генерувати ці знання. Вони надають незаперечну перевагу над конкурентами, допомагаючи знаходити потенційних клієнтів, аналізувати реакцію споживачів на нові продукти, розміщувати більш ефективні стратегії маркетингу, а також розробляти більш якісні продукти.
Процес вилучення структурованої корисної інформації з сайту називається парсингом (parsing), а інструменти для реалізації даного процесу - парсерами (parsers).
Як правило, сайти розробляються з урахуванням того, що зчитувати інформацію з їх сторінок буде людина. Але формат представлених даних, зрозумілий людині, найчастіше не настільки зрозумілий програмним засобам. Крім того, структура представлених даних змінюється від сайту до сайту, тому не існує універсального засобу для вилучення інформації з них. Однак, існують готові рішення, що дозволяють отримувати інформацію з сайту після попередньої конфігурації. Ці рішення часто коштують дорого і не мають тієї гнучкості, яку можуть дати рішення, розроблені під конкретний сайт.
Для того, щоб один раз отримати значення декількох полів з 10-15 сторінок, писати окремий парсер недоцільно, однак в разі великого числа сторінок, полів або високої періодичності збору інформації, цей процес потребує автоматизації [1]. Тому завдання написання системи програмного забезпечення для збору даних, яка накопичує дані дуже важлива.
Web Mining - це процес отримання даних з веб-ресурсів. Так як веб-джерела, як правило, не є текстовими даними, то і підходи до процесу вилучення даних відрізняються в цьому випадку. В першу чергу необхідно пам'ятати, що інформація в інтернеті зберігається у вигляді спеціальної мови розмітки HTML (RSS, Atom та інші), веб-сторінки можуть мати додаткову метаінформацію, а також інформацію про структуру (семантику) документа [6].
Підходи до вилучення даних:
а) аналіз DOM дерева;
б) використання XPath;
в) використання регулярних виразів;
г) візуальний підхід.
У Web Mining можна виділити наступні етапи:
а) вхідний етап (input stage) - отримання "сирих" даних з джерел;
б) етап обробки (preprocessing stage) - дані подаються у формі, необхідній для успішної побудови тієї чи іншої моделі;
в) етап моделювання (pattern discovery stage);
г) етап аналізу моделі (pattern analysis stage) - інтерпретація отриманих результатів.
Існує багато систем для вилучення даних з інтернет-джерел. Найпопулярніші - Datacol, Content Downloader, X-Parser Light, FDE Grabber, WP Uniparser.
В процесі аналізу були виявлені наступні недоліки:
а) багато разів програма звертається в базу даних або в файл;
б) багато часу займають налаштування;
в) в більшості випадків збирається менше 95% даних з порталів;
ґ) іноді на виході отримуємо помилковий контент;
д) виникають помилки при роботі з великими обсягами даних.
Враховуючи їх, було розроблено архітектуру системи збору даних з веб-ресурсів (рис.1). Для реалізації такої системи, яка має назву Extractdata, було використано фреймворк Scrapy, база даних – PostgreSQL та платформа RabbitMQ.
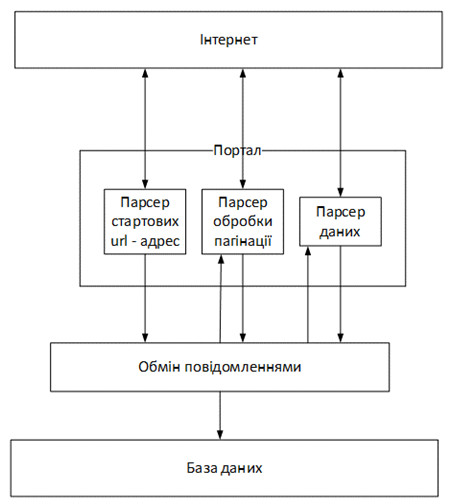
Рисунок 1 - Архітектура системи збору даних з веб-ресурсів
Порівняльний аналіз швидкодії систем збору даних з веб-ресурсів зображено на рис. 2.
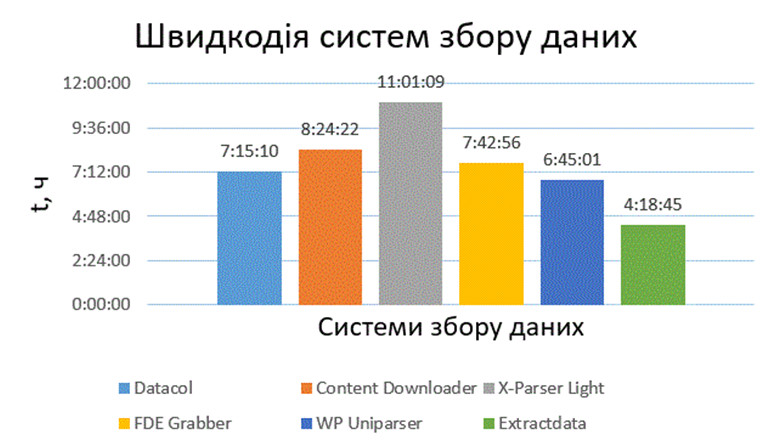
Рисунок 2 – Збір даних з порталу rozetka.com.uа (обхід 100000 цільових сторінок)
У результаті дослідження було виявлено, що обсяг даних в мережі Інтернет зростає за експоненціальною залежністю, тому необхідно розробляти та оптимізувати системи збору даних з веб-ресурсів. Розглянувши існуючі системи збору даних, можна зробити висновок про те, що їх архітектура потребує доробки. Тому, було розроблено систему Extractdata. Для її реалізації було використано фреймворк Scrapy, база даних – PostgreSQL та платформа RabbitMQ.
Література:
1. Web parsing: задачи, проблемы, инструменты [Електронний ресурс]: «Inostudio». – Режим доступу: https://inostudio.com/ru/article/web-parsing.html – Дата доступу: березень 2017. – Загол. з екрану.
2. Data Mining [Електронний ресурс]: «UserGroup». – Режим доступу: http://msugvnua000.web710.discountasp.net/Posts/Details/3316 – Дата доступу: березень 2017. – Загол. з екрану.
3. An introduction to big data [Електронний ресурс]: «Opensource». – Режим доступу: https://opensource.com/resources/big-data – Дата доступу: березень 2017. – Загол. з екрану.
4. Big Data and Data Mining [Електронний ресурс]: «Habrahabr». – Режим доступу: https://habrahabr.ru/post/267827/– Дата доступу: березень 2017. – Загол. з екрану.
5. Data Mining [Електронний ресурс]: «Habrahabr». – Режим доступу: https://habrahabr.ru/post/95209/– Дата доступу: березень 2017. – Загол. з екрану.
6. Document Object Model [Електронний ресурс]: «W3C». – Режим доступу: https://www.w3.org/DOM/ – Дата доступу: березень 2017. – Загол. з екрану.
7. Подходы к извлечению данных с веб-ресурсов [Електронний ресурс]: «Habrahabr». – Режим доступу: https://habrahabr.ru/post/99918/ – Дата доступу: березень 2017. – Загол. з екрану.
8. Подходы к извлечению данных с веб-ресурсов [Електронний ресурс]: «Habrahabr». – Режим доступу: https://habrahabr.ru/company/dataart/blog/262817/ – Дата доступу: березень 2017. – Загол. з екрану.
9. Web Mining: интелектуальный анализ данных в сети Internet [Електронний ресурс]: «Google». – Режим доступу: https://sites.google.com/site/upravlenieznaniami/tehnologii-upravlenia-znaniami/text-mining-web-mining/web-mining – Дата доступу: березень 2017. – Загол. з екрану.
10. Datacol – универсальный парсер с визуализацией сбора данных [Електронний ресурс]: «Рrofithunter». – Режим доступу: https://www.profithunter.ru/obzory/datacol-universalnyiy-parser-s-vizualizatsiey-sbora-dannyih/– Дата доступу: березень 2017. – Загол. з екрану.
11. Datacol – парсер для сбора информации с сайтов [Електронний ресурс]: «Vlada-rykova». – Режим доступу: https://vlada-rykova.com/parser-sajtov/– Дата доступу: березень 2017. – Загол. з екрану.
12. Универсальный парсер контента – программа Content Downloader [Електронний ресурс]: «Seobook». – Режим доступу: http://seobook.info/universalnyy-parser-kontenta/ – Дата доступу: березень 2017. – Загол. з екрану.
13. Перелинковка сайта [Електронний ресурс]: «Рr-cy». – Режим доступу: http://pr-cy.ru/lib/saytostroenie/Perelinkovka-sayta-Kak-eto-sdelat – Дата доступу: березень 2017. – Загол. з екрану.